
Scalyr employs a variety of schemes to efficiently store log data. Each incoming event is parsed into fields and these are stored in a series of columnar databases. Each database file contains a large number of events, all from the same 5-minute time period, each broken into a number of data and metadata fields. Some quick terminology: we refer to each 5-minute columnar database as an “epoch” and – like everyone – we use “field” and “column” interchangeably.
Because they store like values together, columnar databases compress well with off-the-shelf tools like lz4 or zstd. However, for certain data types it can be worthwhile to write your own compression mechanism; in particular, this may allow you to search the compressed form directly without having to expand it.

For example, if every event has a metadata string field like, say, $HOSTNAME, and the total number of distinct strings is relatively low, you can compress this yourself using a custom dictionary that assigns each distinct string to a unique integer. Boom! Instead of storing strings, you’re storing ints. When you’re searching for a string, you can look it up in the dictionary and then just search on the integer (if found – if not, then you know there are no matches). To further lower your storage costs, construct your dictionary with sequential integers starting from zero, and then use a variable-length integer encoding to bring your average storage cost below 4 bytes … and then you run your off-the-shelf compression routine on that =)
A custom dictionary lifecycle has three phases:
- Compression: use a mutable
String -> intmap to replace each string with its int form - Finalization: rewrite this map as a simple
String[], mapping ints back to strings - Decompression: load the
String[]table & resolve each int back to its string
The first two steps each happen once, during compression; the final step happens each time you decompress.
At Scalyr, we took the custom dictionary approach for one metadata field that’s common to all our events: the session/thread field. This field uniquely identifies each thread of execution within each program that is sending us data via our API, and is composed of two strings: a sessionId, which is a globally unique identifier for each API client session, and a threadId, which is what it sounds like: a per-thread name that is unique within a session but may be duplicated in other sessions.
Our initial implementation simply conjoined the two strings into one Pair<String,String> and stored these in a single custom dictionary. Each epoch gets its own dictionary, but often the same strings & pairs repeat across epochs:
Epoch 1: {
// custom dictionary for string pairs
sessionThreadDictionary: [
Pair<"session1", "threadA">, // index 0
Pair<"session1", "threadB">, // index 1
Pair<"session2", "threadB">, // index 2
...
],
// custom-compressed session/thread column, stored as dictionary indices
sessionThreadColumn: [
0, 0, 1, 1, 0, 2, 24, 0, ....
]
}
Epoch 2: {
sessionThreadDictionary: [
Pair<"session1", "threadB">, // index 0, note this pair repeats epoch 1
Pair<"session2", "threadB">, // index 1, " "
...
],
sessionThreadColumn: [
1, 0, 1, 2, 36, 258, 0, 15, 15, ....
]
}*JSON for clarity only; the actual on-disk format is binary
Most columns in an epoch are loaded on-demand into giant byte arrays via the Java unsafe memory accessors, rather than using Java objects; you can read more about that here. However, for a few reasons it made sense to include the session/thread metadata on the java heap as addressable objects.
When reading the metadata for an epoch, then, we also read & load its custom dictionary. Because the session/thread pairs repeat across epochs, we intern each string & each pair so that duplicate values share the same Java object pointer. (Note: we do this interning ourselves, via a simple map, rather than use Java’s String.intern which is can have surprising performance issues).
In the example above, then, we would intern 4 strings: "session1", "session2", "threadA", "threadB". We likewise intern 3 pairs (1/A, 1/B, 2/B); additional epochs that refer to these Strings and Pairs can simply reference the existing object.
This worked well for a few years, but at one point we noticed the intern map was growing beyond our size estimates. When we looked closer, we realized that the pair map was to blame: while the total number of unique sessionId and threadId strings was comfortably low (in the millions), the crossproduct was too large, and storing a separate Pair<> for each combination seen in the wild expanded our memory footprint considerably. This problem was particularly acute in our staging environment, whose servers are provisioned with less RAM than in our production cluster.
We could have solved the problem with a separate dictionary for each string, but we already stored many terabytes of data using single integer values. How could we keep using our single 4 byte pointer to reference 2 strings, in as memory-efficient a structure as possible?
We happened to have a new engineer joining the backend team right as we noticed the problem, and our onboarding process always starts with a “get your feet wet” project. Ideally, these projects are both interesting and self-contained, requiring minimal familiarity with the breadth of our codebase (which familiarity can only come over time). Fixing this custom dictionary problem fit the bill perfectly, so on Oliver’s first or second day he got started from these project notes:
## UPCOMING PROJECT NOTES FOR OLIVER
The static `uniquePairTable` grows too large due to a preponderance of
`threadIds` (we suspect this is due to the way netty and/or grpc manage
their internal threadpools). When you take the crossproduct of these
with `sessionIds`, you get too many things: we saw the unique pair table
grow to > 30M entries on staging, which consumes a _lot_ of java heap
space.
See [internal email thread] for additional information on the problem,
the stopgap, and the proposed solution.
We put in a stopgap measure to drop the intern table every N entries
(`maxUniquePairTableSize`), which has worked to mitigate the GC strain
temporarily; however there's a better solution we want to implement.
Rather than have a java object for each `{sessionId,threadId}` tuple
(represented here as `Pair<String, String>` object), we want to have a
two-step approach:
- Bidirectionally map unique `sessionId` strings to int32 ...
- ... same for `threadId`
- A `{sessionId,threadId}` pair can thus be represented as a 64 bit long
- Bidirectionally map these (sparse) 64 bit longs to 32 bit integers
This gives us our desired `Pair<String,String>-to-int` mapping in as
memory-efficient a format as possible.
Implementation path:
- Replace `uniquePairTable` with a `SequentialIdMap<String>`. Add
interned `sessionId` and `threadId` strings to it separately from one
another
- Replace `threadIds` with a new `LongToSequentialIdMap` that maps 64
bit integers to 32 bit integers. This will be a new class that
presents a `SequentialIdMap`-like interface but operates on primitive
64 bit longs rather than generic Objects. Note that `SequentialIdMap`
is built from multiple generic classes ({@link ThreadSafeIdMap}, etc),
each of which will need to be ported accordingly. This should be a
mostly-mechanical effort, although porting SemiLockFreeHashMap
looks fun. Open addressing! Linear probing! How often do you get to write a hashtable in real life? =)
- Any interface work required to support clients that expect to pass us `Pair<String, String>` objects and get back 32 bit integers in return, and vice-versa. It's possible/likely that no changes are required, but maybe there are some corner cases _or_ optimizations where clients can pass 2 strings separately rather than as a `Pair`.
- Remove the knobs relating to dropping the `uniquePairTable`
- Tests, of course, both for the new `LongToSequentialIdMap` class and
for overall correctness
Looking again at our prior example, our storage format now becomes:
Epoch 1: {
// custom dictionary for single strings
sessionOrThreadDictionary: [
"session1", // index 0
"threadA", // index 1
"threadB", // index 2
"session2", // index 3
...
],
// our original pairs, now stored as an array of longs
sessionThreadPairs: [
0 << 32 | 1, // index 0, aka Pair<"session1", "threadA">
0 << 32 | 2, // index 1, aka Pair("session1", "threadB">
3 << 32 | 2, // index 2, aka Pair("session2", "threadB">
],
// unchanged from above
sessionThreadColumn: [
0, 0, 1, 1, 0, 2, 24, 0, ....
]
}
Epoch 2: {
// custom dictionary for strings
sessionOrThreadDictionary: [
"session1", // index 0
"threadB", // index 1
"session2", // index 2
...
],
// our original pairs, now stored as an array of longs
sessionThreadPairs: [
0 << 32 | 1, // index 0, aka Pair<"session1", "threadB">
2 << 32 | 1, // index 1, aka Pair("session2", "threadB">
],
// unchanged from above
sessionThreadColumn: [
1, 0, 1, 2, 36, 258, 0, 15, 15, ....
]
}But wait, what about the quadratic part?
Having fixed the memory problem, we felt pretty good. For a couple of days.
We then noticed some regressions in staging performance – anecdotally, just from using the product, and also reflected in our metrics. At Scalyr we are all about “speed to truth“, so we drilled from metrics into logs into stack traces (all within a couple of clicks, pretty awesome) and realized that we were spending an unexplainable amount of time doing lookups in our long -> int map. And by “unexplainable” I mean that sinking “this must be doing something quadratic” feeling.
Which really didn’t make sense: the new long -> int maps were storing the exact same data as the Pair<String,String> -> int maps they replaced … and those maps never showed up in our stack profiles before. In other words:
pairMap.get(new Pair("foo", "bar)); // fast
longMap.get(3 << 32 | 18); // sloooooooooooowMaps are supposed to provide constant time lookup, and yet changing our key type meant we were suddenly sublinear. What was going on?
There’s a hint in the project notes from above, I’ll copy it here:
This should be a mostly-mechanical effort, although porting
SemiLockFreeHashMap looks fun. Open addressing! Linear probing!
How often do you get to write a hashtable in real life? =)Some of you may have already twigged to the issue: open addressing. There are many different ways to implement maps; open addressing uses a simple array, with keys in the even-numbered indices and values in the odds. Our existing StringPair -> int map already used open addressing, and it was an even more natural fit for the replacement long->int map: both the keys and values are primitives, so the whole thing is just a slab of contiguous memory without a pointer anywhere in the mix.
So what went so wrong?
Open addressing works by hashing a key to its hashcode and looking at the corresponding slot in the array; if that slot is occupied by a different key it then steps forward to the next key (“linear addressing”) and checks that key for equality, repeating this sequence we land on either the desired key or an empty slot (in which case the map does not contain the key). In other words, subsequent entries in the base array take the place of the linked buckets that hold colliding keys in a standard hashtable.
The wikipedia article on open addressing has a great example diagram:
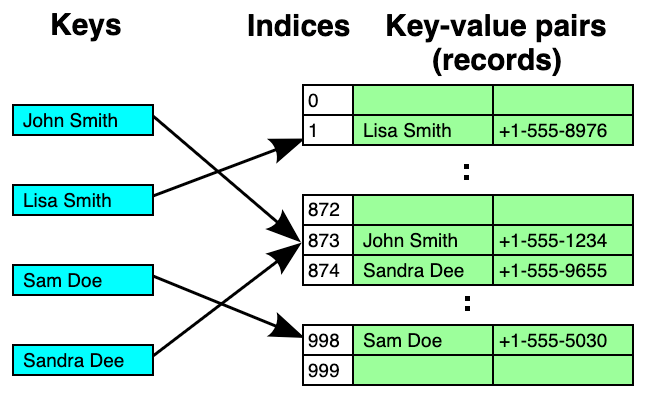
In the diagram above, we see that John Smith and Sandra Dee both hash to index 873, so Sandra Dee ends up stored in slot 874. The diagram shows a run of only two occupied slots, but you can imagine the consequences if there were a run of 1,000 or more occupied slots: every get() or put() that lands in the run will have to walk forward over hundreds of values, doing equality tests at each one.
As a result, performance is heavily dependent on using a hash function that distributes your keys evenly. If you have this, then your runs will be short and you’ll observe good performance – just like we had when the map keys were String pairs. But, when we switched to longs, that was no longer the case. What was going on?
Our initial implementation naturally used the standard library function: Long.hashCode(long value) … but let’s take a closer look at that:
// java.lang.Long
public static int hashCode(long value) {
return (int)(value ^ (value >>> 32));
}Turns out the default implementation simply XORs the high & low 32 bits, making it an almost comically poor choice for our dataset. Remember we create our long keys by conjoining 2 integers into the high & low 32 bits … and those integers themselves are (by design) assigned sequentially starting from zero.
As an example, let’s assume we have 30,000 unique sessionId values, and another 30,000 unique threadId values. Each of these string values is mapped to an integer in the range [0, 60000), and then these are conjoined into longs … which Long.hashCode breaks back apart and XORs:
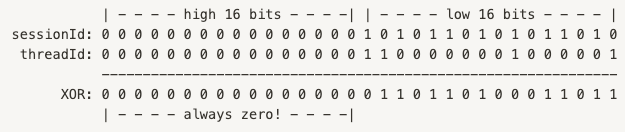
The actual values above aren’t important – what is important is to recognize that the relatively low cardinality of our string set (60,000) means the high 16 bits of each XOR input – and thus the output – will always be zero.
Of course, while the two integers themselves are small, their crossproduct isn’t: with 30,000 distinct values of each type, we have close to a billion possible longs as input to our hash function. But, when that hash function is Long.hashCode, the output of that function is guaranteed to use only the low-order 16 bits … so our ~1B possible inputs map to 65,536 possible outputs … and, even worse, they are all sequential in the range [0,65536) – guaranteeing large runs of hash collisions.
Put another way: all of our entropy is clustered in the low-order portion of the high & low 32 bits, and Long.hashCode concentrates all of that entropy into low-order bits of the returned int. And by “concentrates” I mean “destroys” … sigh.
This led to a single-line fix, using a hash function which we already had in our internal utilities:
// Hash the key to find an initial search index.
- int index = (Long.hashCode(key) & ...;
+ int index = ((int)Util.highQualityIntHash64(key) & ...;While that fixed the problem, the actual PR wasn’t complete until the javadoc was up-to-date. Otherwise, a future maintainer might wonder why we’re using custom code when the runtime already comes with one. When correctness or performance are sensitive to subtle issues, it’s best to call these out explicitly to head off future Chesterton’s fence-type issues. So the majority of the PR (outside of tests) was a new chunk of javadoc in the relevant map class:
* Our implementation uses open addressing with linear probing: if key K
* appears in the table, it will be at `table[hashCode(K) % (table.length
* / 2)) * 2]` or at a subsequent position reached by advancing two slots
* at a time (mod table.length).
*
* Linear probing is sensitive to clustering, so we require a hash
* function that distributes our keys evenly across the table, with
* "gaps" between sequential runs of used slots - a lack of gaps will
* drive lookups from O(1) to O(N). In particular, we want a hash
* function that deals well with our particular key domain: longs
* composed of two integers in the high & low 32 bits, and with those
* integers being assigned sequentially from zero rather than randomly.
* Java's native Long.hashCode function is comically poorly suited * for this use case, as it simply XORs the high & low 32 bits.
So there we have it! A day (week) in the life of a new Scalyr engineer: fun low-level projects, unexpected issues, and thankfully we have Scalyr itself to help us figure all this out. Without the ability to quickly navigate from alerts to logs to graphs & back again, diagnosing this issue would have been much harder.

