
There’s always lots of data whenever you check your logs. For every action that you process on your machine, the system keeps a record of it. For instance, when you run some codes on your system, your browser’s console creates logs. This doesn’t end with you running codes alone, as there are countless places where logs are necessary.
How about getting real-time logs from applications you deploy on servers? For example, you don’t want to miss out on whatever process your application goes through. You’ll want to know when your servers are down or when your application begins to malfunction. Logs capture all these records and sometimes even detect some malfunctions before they happen.
At some point, logs become too big, and there’s a need to organize them for easy access. What this means is that there has to be a way to sort and arrange logs so you can find the important ones quickly. Logs that are alike need to be kept together so that users can get them as quickly as possible.
This is where log indexing comes in.

What Is Log Indexing?
It’s a way to sort logs so that users can access them quickly. Log indexing is a method of log management where logs are arranged as keys based on some attributes. Indexing engines also provide faster access to query logs.
This seems a lot like book indexing. However, a book index is usually in subject order. In contrast, log indexing arranges files based on chronological order and in other ways.
Although log indexing may use chronological order, there are many other options. For instance, you can index logs according to IDs or usernames. All you need to do is create an index with an attribute of your choice.
Creating log indexes will generate different keys that are stored in servers. Searching logs becomes easy with the help of keys, as they point users to their original position in servers.
Why Is Log Indexing Important?
Indexing allows efficiency and speed. In this section, we’ll look at different reasons to index your logs. We’ll also discuss the pros that indexing logs offer, and why it’s an important step.

Optimize Query Efficiency
This is the main reason lots of people love to index logs. It’s necessary because logs become pretty big over time. And developers should be able to find whatever data they need as quickly as possible.
For instance, you may want to search your logs and fish out all logs with “error” criticality. When logs become too big, you may want to attend to them starting from “errors” down to “messages.” But it’ll take a long time to search several hundred log messages. Therefore, indexing them before search is a great idea. Indexed log searching significantly reduces time when compared to logs in their crude state.
Efficient Sorting
Since logs tend to become huge over time, sorting is always a welcome idea. What indexing does is to arrange logs in a manner that will allow developers to pinpoint data faster. Sorting make logs more readable, easy to find, and easy to access.

Avoid Duplicate Logs
In your log tables, you can prevent duplicate log files with the use of unique indexing. Unique indexes make sure that no two rows contain the same value. You can require keys to be checked for uniqueness to avoid duplicate logs. This process helps in sorting logs and ensuring querying logs are efficient.
How Log Indexing Works
You use log indexing because you don’t want to search through all your logs whenever you need a particular record. This method lets you fetch the right logs swiftly. In this section, we’ll look at how log indexing really works and how it arranges log files.
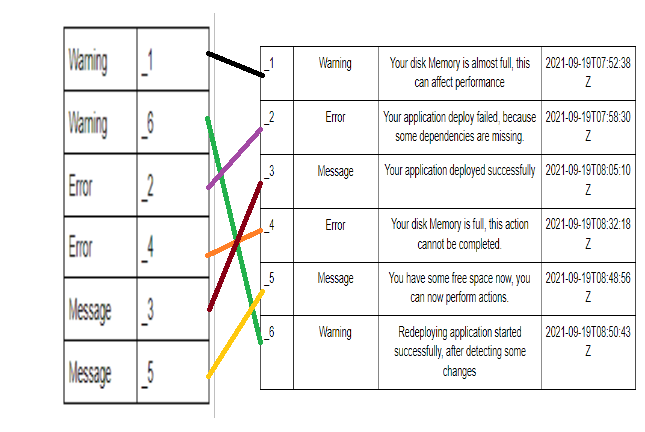
Let’s look at the table below, which consists of unordered (unindexed) logs.
Unordered Table
| Warning | Your disk memory is almost full. This can affect performance. | 2021-09-19T07:52:38Z |
| Error | Your application deploy failed because some dependencies are missing. | 2021-09-19T07:58:30Z |
| Message | Your application deployed successfully. | 2021-09-19T08:05:10Z |
| Error | Your disk memory is full, so this action cannot be completed. | 2021-09-19T08:32:18Z |
| Message | You have some free space now. You can perform actions. | 2021-09-19T08:48:56Z |
| Warning | Redeploying application started successfully after detecting some changes. | 2021-09-19T08:50:43Z |
The logs in this example are crude, and real logs aren’t ordered as shown in the table above.
From the table above, if we try to query our table, then all entries will be queried. For instance, if we try to find all the logs with “Error” criticality, all six rows have to be searched. This action will cost time, as searching of all columns needs to be done carefully. Therefore, the best option is to index log files. Let’s see how that looks.
Ordered Table
| Warning | Your disk memory is almost full. This can affect performance. | 2021-09-19T07:52:38Z |
| Warning | Redeploying application started successfully after detecting some changes. | 2021-09-19T08:50:43Z |
| Error | Your application deploy failed because some dependencies are missing. | 2021-09-19T07:58:30Z |
| Error | Your disk memory is full, so this action cannot be completed. | 2021-09-19T08:32:18Z |
| Message | Your application deployed successfully. | 2021-09-19T08:05:10Z |
| Message | You have some free space now. You can perform actions. | 2021-09-19T08:48:56Z |
Logs in the table above are ordered. As a result, if you search for logs with “Error” criticality, only the last two rows will be searched. This will save time whenever you query your logs.
However, the log table doesn’t rearrange itself whenever there’s a change in query conditions. Instead, the log table creates a B-tree data structure. In other words, our logs will be sorted to match whatever query we make on our system. This means only the most critical information will be present in our data structure.
The data structure created will contain pointers (keys) and essential information called indexes. Once you query your logs, the system searches that crucial information and finds the result. Then, the keys will find the rest of the information from the database.
The diagram below shows how indexing really works, only the indexes are ordered and the log table remains unchanged.
How to Do Things Better
In this article, we’ve explored what log indexing really is. We’ve also discussed how log indexing works and the advantages of indexing logs. Although the log management method we just discussed might seem like the best log management method, it isn’t.
With log indexing comes the problem of space management. This is because indexes are stored on disk space, so every new key you create gets stored in the disk. The amount of disk space, however, depends on the number of columns used for indexing. This is a big problem that comes with indexing log data.
Another problem with this log management method is the need to build and rebuild indexes. Every time log data is modified, the indexing engine has to update itself. This process involves updating all indexes. Therefore, it slows down server performance and costs developers time.
All of these reasons and more are why organizations like Scalyr have come up with the no-indexing method.
What’s the No-Indexing Method?
This log management method shifts from the traditional keyword indexing to a column-oriented log management system. In this approach, the system injects incoming data into a NoSQL columnar database to give developers a better real-time view into their data.
The advantages of this method are:
- Less consumption of computing space
- No rebuilding of indexes
- Improved server performance
You may want to try Scalyr and see for yourself.

