
Previously on SKREAM…
In our previous SKREAM post, we discussed kernel pool overflow vulnerabilities and presented a new mitigation meant to thwart the use of a specific exploitation technique on Windows 7 and 8 systems. This mitigation was later incorporated into our open source kernel-mode exploit mitigations kit, dubbed SKREAM.
Even though the specific technique we mitigated there (crafting a malicious OBJECT_TYPE structure at 0xbad0b0b0) was eliminated on Windows 8.1, pool overflow vulnerabilities still remain a prevailing issue on modern systems and are being actively exploited through different, more complex methods. With that in mind, we wanted to take SKREAM a step further and address pool overflow vulnerabilities in a more generic way, one which could mitigate this type of attack regardless of the specific techniques employed.
There are several key premises for a successful exploitation of pool overflows. A major one is that attackers must be able to craft the overflowing buffer very carefully, knowing precisely what data they are planning to write over and leaving the rest intact. This means that any misplaced byte would probably trash the next pool allocation in an unexpected manner, resulting in a very likely Blue Screen of Death.
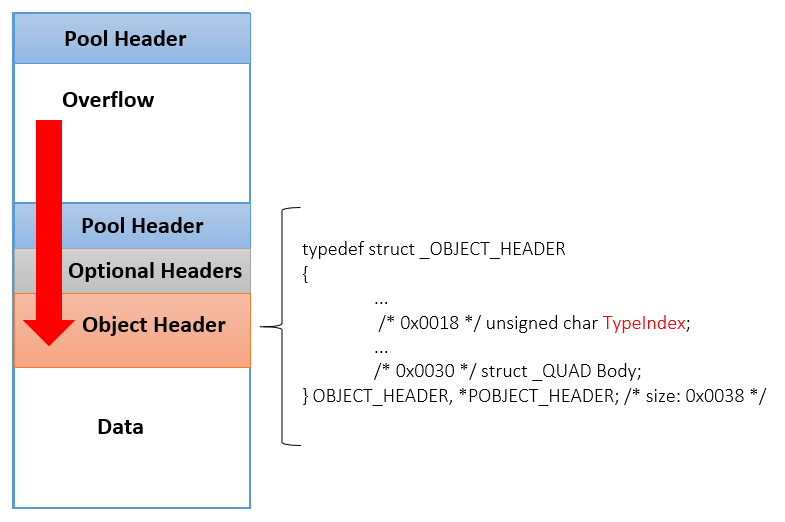
Figure 1 – An illustration of a pool overflow. For example, in a TypeIndex overwrite attack, the exploit attempts to set ObjectHeader.TypeIndex of the next pool block to either 0 or 1.
To do so, it must calculate the exact distance of the ObjectHeader from the beginning of the overflowing buffer, and the offset of the TypeIndex member in it.
Taking into account the byte-level precision required on the attacker’s behalf, we can break most exploits of this class by introducing some degree of randomization to pool allocations. When randomizing a pool allocation, we have two possible courses of action – we can either choose to shift (or slide) the allocation or we can simply bloat it. Both of these methods ultimately aim to make the size of the necessary overflow unknown to the attacker, each with its own relative advantages and disadvantages.
PoolSlider
AKA the risky method, AKA vm-destroyer
As stated by the WDK documentation, a key attribute of the kernel pool allocator on x64 is that all allocations must be aligned and rounded up to 16 bytes (or 8 bytes on x86). This means that any allocation whose requested size is not an exact multiple of 16, will receive an extra few bytes of padding, so as to round-up its size to match the pool granularity.
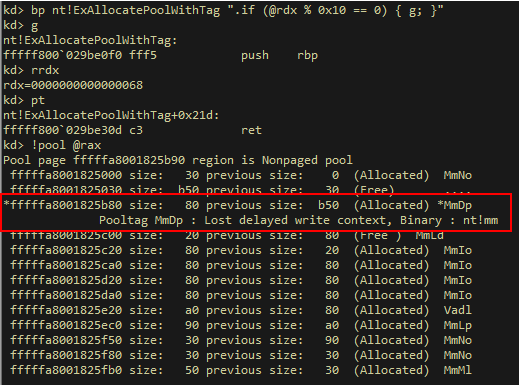
Figure 2 – A pool allocation with a requested size (rdx) of 0x68 bytes.
The final block size is 0x80 bytes: pool header (0x10) + requested size (0x68) + padding (0x8)
Obviously, an attacker trying to overflow such an allocation would have to account for the extra padding bytes added by the pool manager. For example, in the allocation shown in figure 2, there are 0x70 bytes that would have to be overwritten before reaching the next pool allocation, even though only 0x68 were requested by the caller.
In our PoolSlider mitigation, we take advantage of this padding and “slide” (i.e. advance) the pointer returned to the caller by a random number of bytes. By doing so we implicitly create some padding at the beginning of the pool block, while decreasing the amount of padding found at the end. This effectively breaks the predictability of pool overflow exploits – the attacker would try to account for the padding bytes, but since the entire allocation was shifted the exploit would not write the expected data to the planned locations.
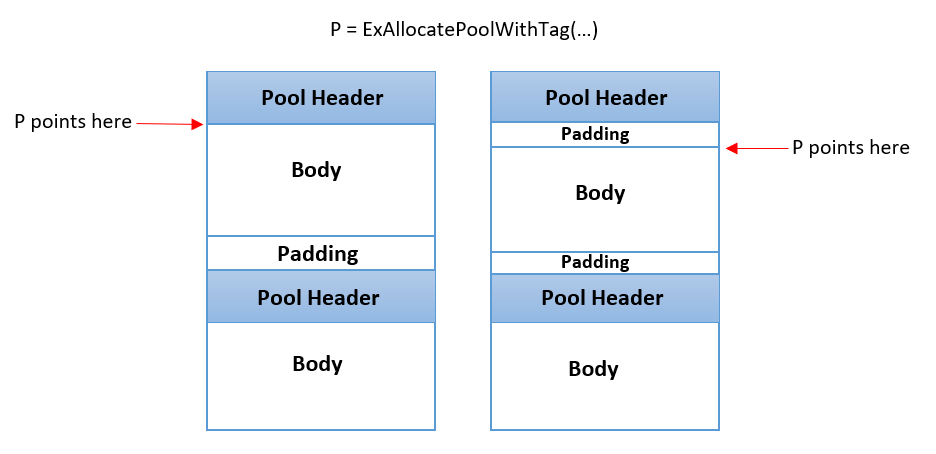
Figure 3 – A pool allocation, with (right) and without (left) PoolSlider.
We implemented this mitigation by extending SKREAM to monitor image load events and placing a IAT hook on ExAllocatePoolWithTag for every newly loaded driver. Whenever a pool allocation is made, our hook calculates the number of padding bytes that were added to it. It then generates a random number between 1 and the amount of available padding, and advances the pointer returned to the caller by that number.
Handling Frees
Of course, by advancing the pointer returned to the caller we break the predictability of the pool, but not just for the potential attacker. A key assumption made by the pool manager is that the pointer returned to the caller is immediately preceded by a POOL_HEADER structure describing the allocation. This means that when trying to free a pool block denoted by ‘P’ (e.g. by calling nt!ExFreePoolWithTag) the pool manager will search for the pertinent pool header at <P – sizeof(POOL_HEADER)>. Needless to say, this assumption breaks completely when PoolSlider is enabled, and the system will crash with bugcheck 0x19 (BAD_POOL_HEADER).
To properly handle frees, we had to place an additional IAT hook on ExFreePoolWithTag and re-align the pointer to 16 bytes before actually freeing it.

Other Issues
When testing PoolSlider we encountered a few more issues. Some were relatively easy to solve, while others still pose significant challenges for this mitigation:
- Allocating with ExAllocatePoolWithTag and freeing with ExFreePool or vice versa – this can be solved by simply hooking both ExAllocatePool and ExFreePool and making the same randomization / re-alignment actions as we do in Ex{Allocate, Free}PoolWithTag.
- Allocating a string with ExAllocatePool(WithTag) and freeing it with RtlFree{Ansi, Unicode}String – This is a poor programming practice, as strings should be allocated using the matching allocation routines. Internally, these freeing functions forward the ‘Buffer’ member of the string object to ExFreePool(WithTag), causing a system crash if the pointer is not properly aligned to 16. This can be fixed by simply placing additional IAT hooks on RtlFree{Ansi, Unicode}String, and re-aligning the pointer the same way we do in ExFreePool(WithTag).
- Lookaside lists heads allocated in the pool – some drivers initialize lookaside lists during their initialization using nt!ExInitializeLookasideListEx. The first parameter this function receives is “PLOOKASIDE_LIST_EX Lookaside”. According to the MSDN documentation:

Most drivers keep this structure as a global variable in the driver’s data section, but some choose to dynamically allocate it in the pool. Since our mitigation “randomizes” the pointer address returned to the caller, in such cases the start address of this structure is not 16-byte aligned, causing error 0x80000002 (STATUS_DATATYPE_MISALIGNMENT) to be raised when nt!ExInitializeLookasideListEx is called. - Memory allocated by one driver, freed by another – the most complex case we encountered is where one driver allocates pool memory and another one (usually NTOS) frees it. In such cases, when the freeing driver is not hooked, we cannot re-align the pointer before ExFreePool gets called, causing a BSOD with bugcheck 0xC2 (BAD_POOL_CALLER).
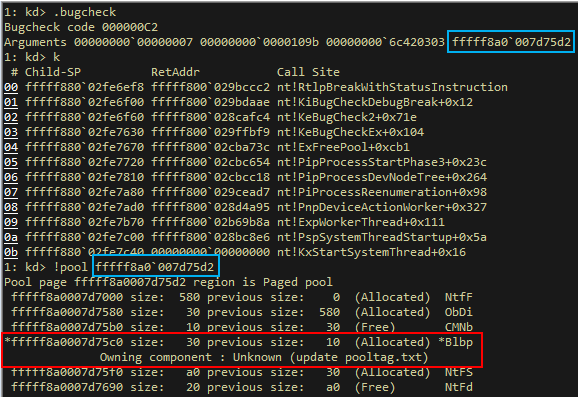
Figure 4 – A pool allocation with tag “Blbp” that was allocated by Blbdrive.sys is later freed directly by NTOS. Notice that the address of the pool block is not aligned to 0x10, causing bugcheck 0xC2.
Another issue we haven’t addressed so far is the case of pool allocations whose requested size is an exact multiple of 16. In these cases there is no extra padding, and thus PoolSlider cannot advance the pointer returned to the caller. Currently we chose to ignore this case, leaving it as a known gap of this mitigation.
However, this problem could be solved by creating “artificial” padding at the end of an aligned pool block. Simply adding 1 to the requested size of the allocation will cause the pool manager to add another 15 bytes of padding, so as to re-align the block size back to 16. Then we have some padding we can play with, at the cost of “wasting” some pool memory unnecessarily.

PoolSlider vs. HEVD
We tested PoolSlider against a sample exploit, abusing a non-paged pool overflow vulnerability found in HEVD:
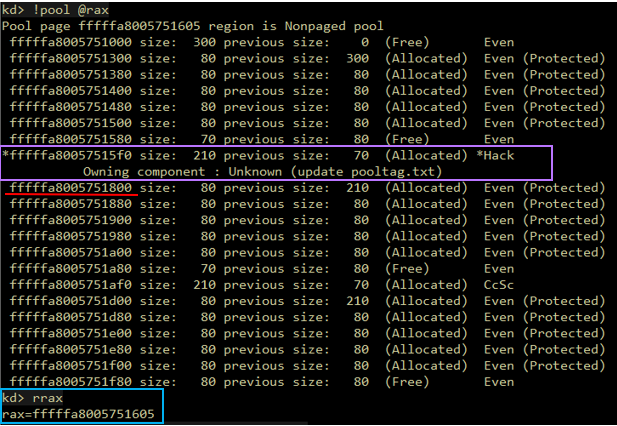
Figure 5.1 – A pool allocation that will later be exploited. Notice that the pointer returned to the caller (saved in the rax register) was shifted by 5 bytes.
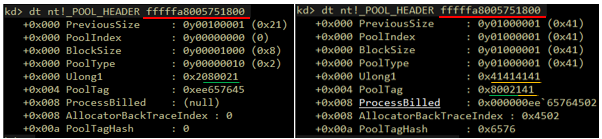
Figure 5.2 – The header of the next pool block, before and after the overflow. As can be seen, the exploit failed to preserve the original pool header. In this particular case the overflow is off by 5 bytes, since PoolSlider shifted the pointer.
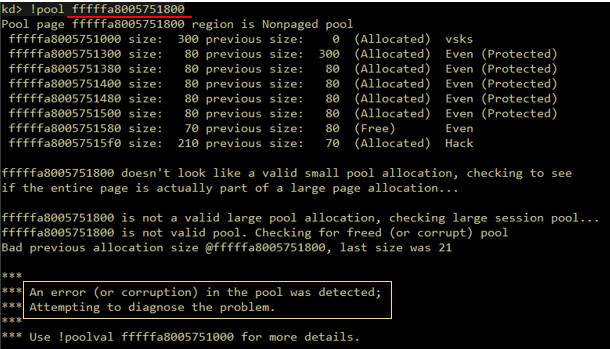
Figure 5.3 – The exploit corrupted the next header and failed to preserve the integrity of the pool. This will eventually lead to a bugcheck.
PoolBloater
AKA the resource-waster, AKA got-my-vm-to-start
The second and far simpler approach for mitigating pool overflows does not change the base address of the allocation at all. Rather, it increases (i.e. “bloats”) the size of the requested pool allocation by a random amount of bytes, thus sabotaging the precision of a potential exploit.
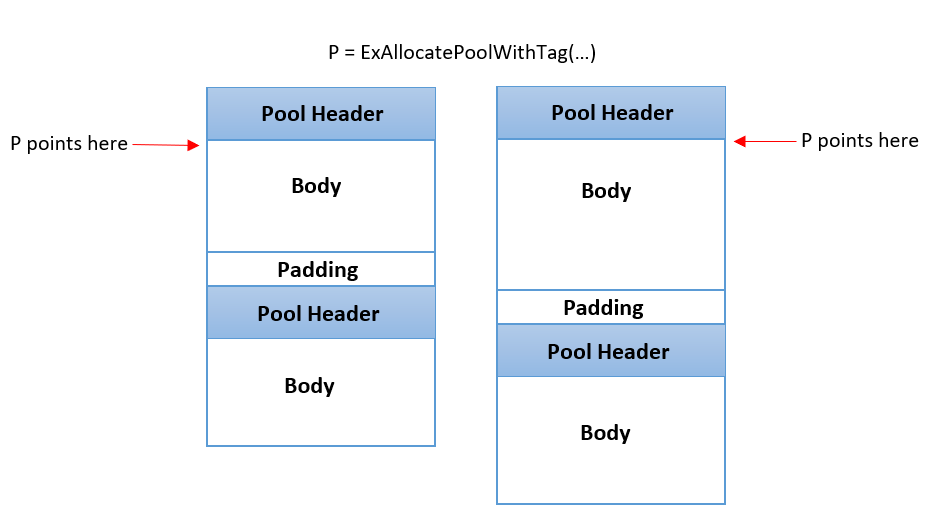
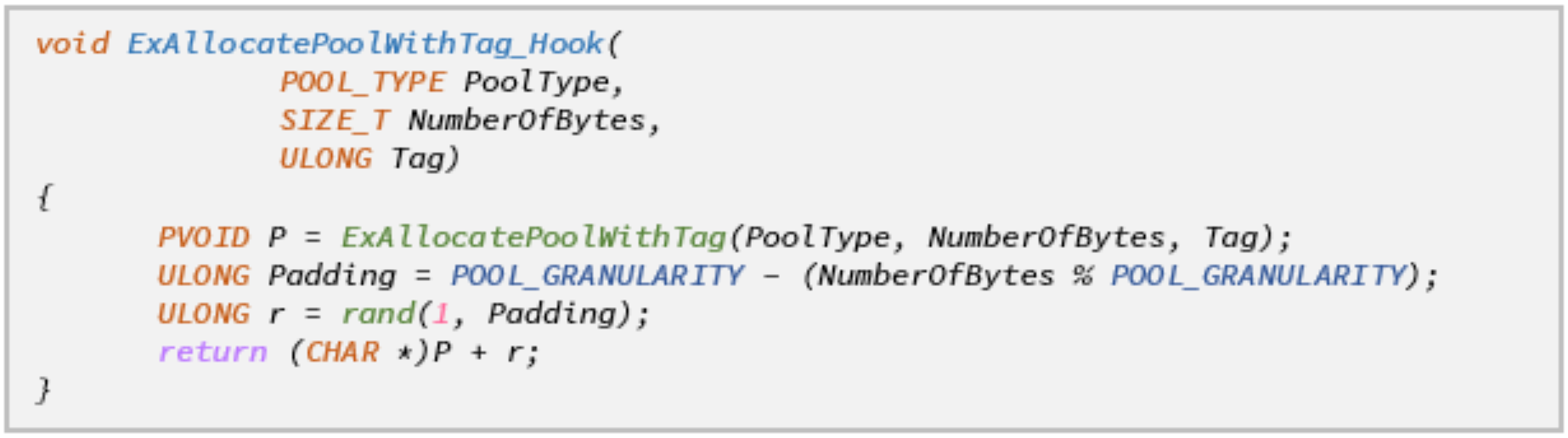
Figure 6 – A pool allocation, with (right) and without (left) PoolBloater.
The implementation of PoolBloater is very simple compared with PoolSlider. We hook ExAllocatePool(WithTag) the same way we do in PoolSlider, and only change the action taken inside the hook:

The main advantage of this approach is that it implicitly avoids most of the issues we encountered while experimenting with PoolSlider. Since we only change the size of the pool block, we don’t have to face problems that stem from pointer mis-alignment. Another clear advantage of this method is that it effectively renders pool spraying techniques useless. Because the size of the overflowing block is randomized, chances are it won’t fit into the “holes” created by the pool spray, and will be allocated at an unexpected location.
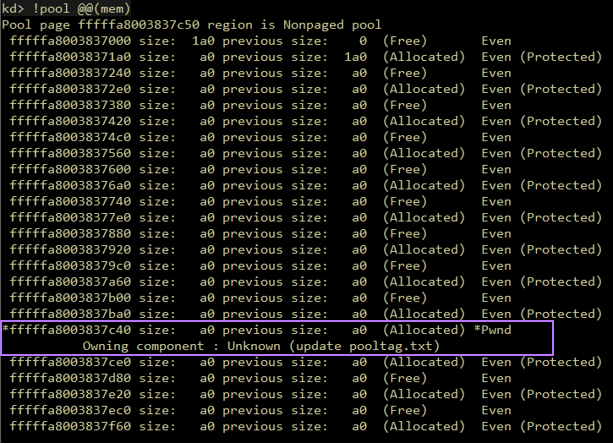
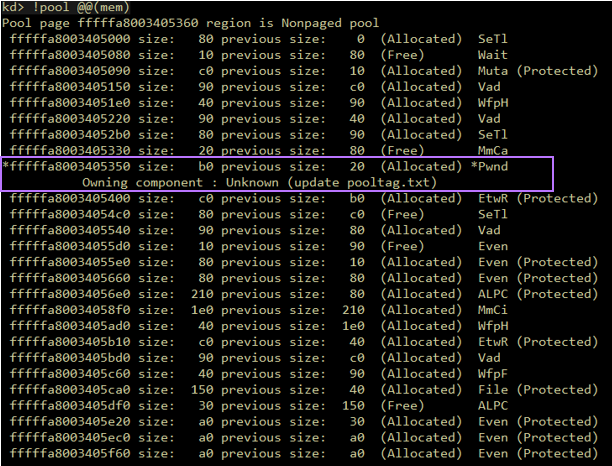
Figure 7 – A vulnerable pool allocation, made with (down) and without (up) SKREAM. Without PoolBloater, the vulnerable allocation inhabits the “hole” created after spraying the pool with event objects. With PoolBloater enabled, the allocation size becomes larger and so it doesn’t fit in the designated “hole”, so it is allocated somewhere else, followed by an unknown allocation that cannot be controlled by the attacker.
The clear disadvantage of this method though, is that pool memory utilization can become much higher than usual, depending on the amount of bytes added to each allocation. Generally speaking, this mitigation exhibits an inherent tradeoff – choosing a high upper bound for our randomization will lead to a stronger mitigation, at the cost of being more resource-intensive. On the other hand, choosing a low upper bound for our randomization will cause the pool utilization to remain rather normal, but make the mitigation weaker.
Known Limitations
Both implementations suffer from a few inherent shortcomings, caused mainly by other system mechanisms (such as PatchGuard) which limit our ability to monitor every driver in the system and most notably the kernel executable itself (NTOSKRNL). Therefore we only attempt to deal with a proper subset of pool overflow exploits for now, and hope to incrementally improve our coverage in future projects.
For now, both of our mitigations suffer from the following limitations:
- We only protect drivers that are not an integral part of the Windows operating system.
- We only protect drivers that load after SKREAM.
- We only protect allocations done directly by the faulting driver through ExAllocatePool(WithTag). Any allocation done by the system is left unprotected, even if it is later forwarded to a 3rd party driver for further processing (for example – SystemBuffer for IOCTLs).
- We only protect allocations that fit nicely within a page. (bigger allocations which span a page or more are handled differently by nt!ExpAllocateBigPool)
- We (still) haven’t implemented unhooking, which basically means SKREAM can’t be unloaded without risking in crashing.
- If SKREAM is compiled with PoolSlider enabled, its service cannot be configured to start as “system” but only as “auto” (otherwise the OS will probably crash). In any case, use this kit at your own risk.

