


Hashing is a fundamental concept in cryptography and information security. Our guide explores the principles of hashing, explaining how cryptographic hash functions work and their importance in protecting sensitive data.
Learn about the different types of hash functions, their properties, and common applications such as password storage, data integrity verification, and digital signatures. Discover how to choose the right hash function for your specific use case and implement secure hashing practices in your organization.

What is a Hashing Algorithm?
Hashes are the output of a hashing algorithm like MD5 (Message Digest 5) or SHA (Secure Hash Algorithm). These algorithms essentially aim to produce a unique, fixed-length string – the hash value, or “message digest” – for any given piece of data or “message”. As every file on a computer is, ultimately, just data that can be represented in binary form, a hashing algorithm can take that data and run a complex calculation on it and output a fixed-length string as the result of the calculation. The result is the file’s hash value or message digest.
To calculate a file’s hash in Windows 10, use PowerShell’s built in Get-FileHash cmdlet and feed it the path to a file whose hash value you want to produce. By default, it will use the SHA-2 256 algorithm:

You can change to another algorithm by specifying it after the filepath with the -Algorithm switch. Passing the result to Format-List also gives a more reader-friendly output:
For Mac and Linux users, the command line tools shasum and md5 serve the same purpose. As we’ll see in a moment, regardless of whether you’re using Windows, Mac or Linux, the hash value will be identical for any given file and hashing algorithm.
How Hashes Establish Identity
Hashes cannot be reversed, so simply knowing the result of a file’s hash from a hashing algorithm does not allow you to reconstruct the file’s contents. What it does allow you to do, however, is determine whether two files are identical or not without knowing anything about their contents.
For this reason, the idea that the result is unique is fundamental to the whole concept of hashes. If two different files could produce the same digest, we would have a “collision”, and we would not be able to use the hash as a reliable identifier for that file.
The possibility of producing a collision is small, but not unheard of, and is the reason why more secure algorithms like SHA-2 have replaced SHA-1 and MD5. For example, the contents of the following two files, ship.jpg and plane.jpg are clearly different, as a simple visual inspection shows, so they should produce different message digests.

However, when we calculate the value with MD5 we get a collision, falsely indicating that the files are identical. Here the output is from the command line on macOS using the Terminal.app, but you can see that the ship.jpg hash value is the same as we got from PowerShell earlier:

Let’s calculate the hash value with SHA-2 256. Now, we get a more accurate result indicating the files are indeed different as expected:

What is Hashing Used For?
Given a unique identifier for a file, we can use this information in a number of ways. Some legacy AV solutions rely entirely on hash values to determine if a file is malicious or not, without examining the file’s contents or behavior. They do this by keeping an internal database of hash values belonging to known malware. On scanning a system, the AV engine calculates a hash value for each executable file on the user’s machine and tests to see if there is a match in its database.
This must have seemed like a neat solution in the early days of cyber security, but it’s not hard to see the flaws in relying on hash values given hindsight.
First, as the number of malware samples has exploded, keeping up a database of signatures has become a task that simply doesn’t scale. It has been estimated that there are upwards of 500,000 unique malware samples appearing every day. That’s very likely due in large part to malware authors realizing that they can fool AV engines that rely on hashes into not recognizing a sample very easily. All the attacker has to do is add an extra byte to the end of a file and it will produce a different hash.
This is such a simple process that malware authors can automate the process such that the same URL will deliver the same malware to victims with a different hash every few seconds.
Second, the flaw in legacy AV has always been that detection requires foreknowledge of the threat, so by-design an anti-malware solution that relies on a database of known hash values is always one-step behind the next attack.
The answer to that, of course, is a security solution that leverages behavioral AI and which takes a defense-in-depth approach.
However, that doesn’t mean hash values have no value! On the contrary, being able to identify a file uniquely still has important benefits. You will see hash values provided in digital signatures and certificates in many contexts such as code signing and SSL to help establish that a file, website or download is genuine.
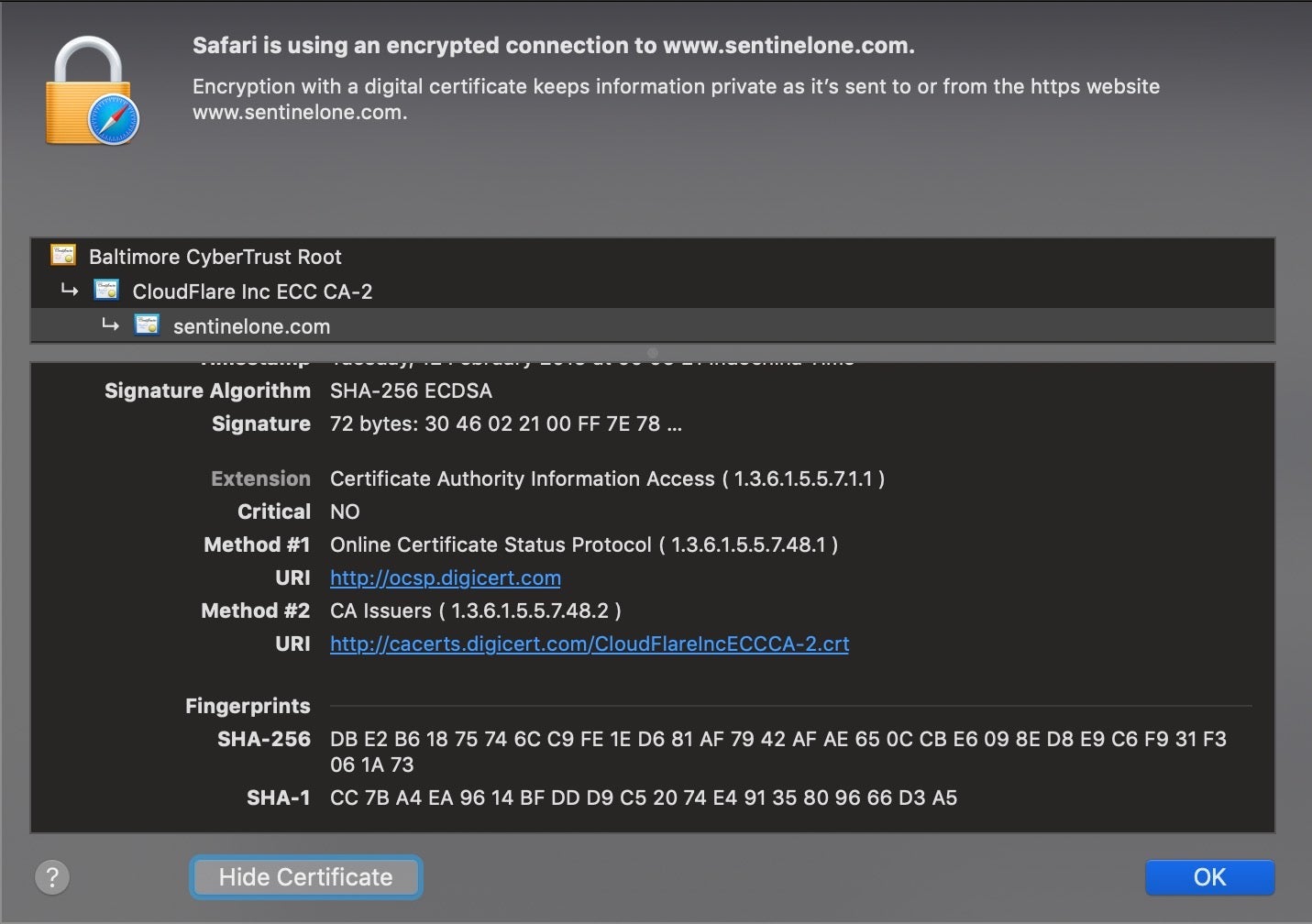
Hash values are also a great aid to security researchers, SOC teams, malware hunters, and reverse engineers. One of the most common uses of hashes that you’ll see in many technical reports here on SentinelOne and elsewhere is to share Indicators of Compromise. Using hash values, researchers can reference malware samples and share them with others through malware repositories like VirusTotal, VirusBay, Malpedia and MalShare.
Benefits of Hashes in Threat Hunting
Threat hunting is also made easier thanks to hash values. Let’s take a look at an example of how an IT admin could search for threats across their fleet using hash values in the SentinelOne management console.
Hashes are really helpful when you identify a threat on one machine and want to query your entire network for existence of that file. Click the Visibility icon in the SentinelOne management console and start a new query. In this case, we’ll just use the file’s SHA1 hash, and we’ll look for its existence over the last 3 months.
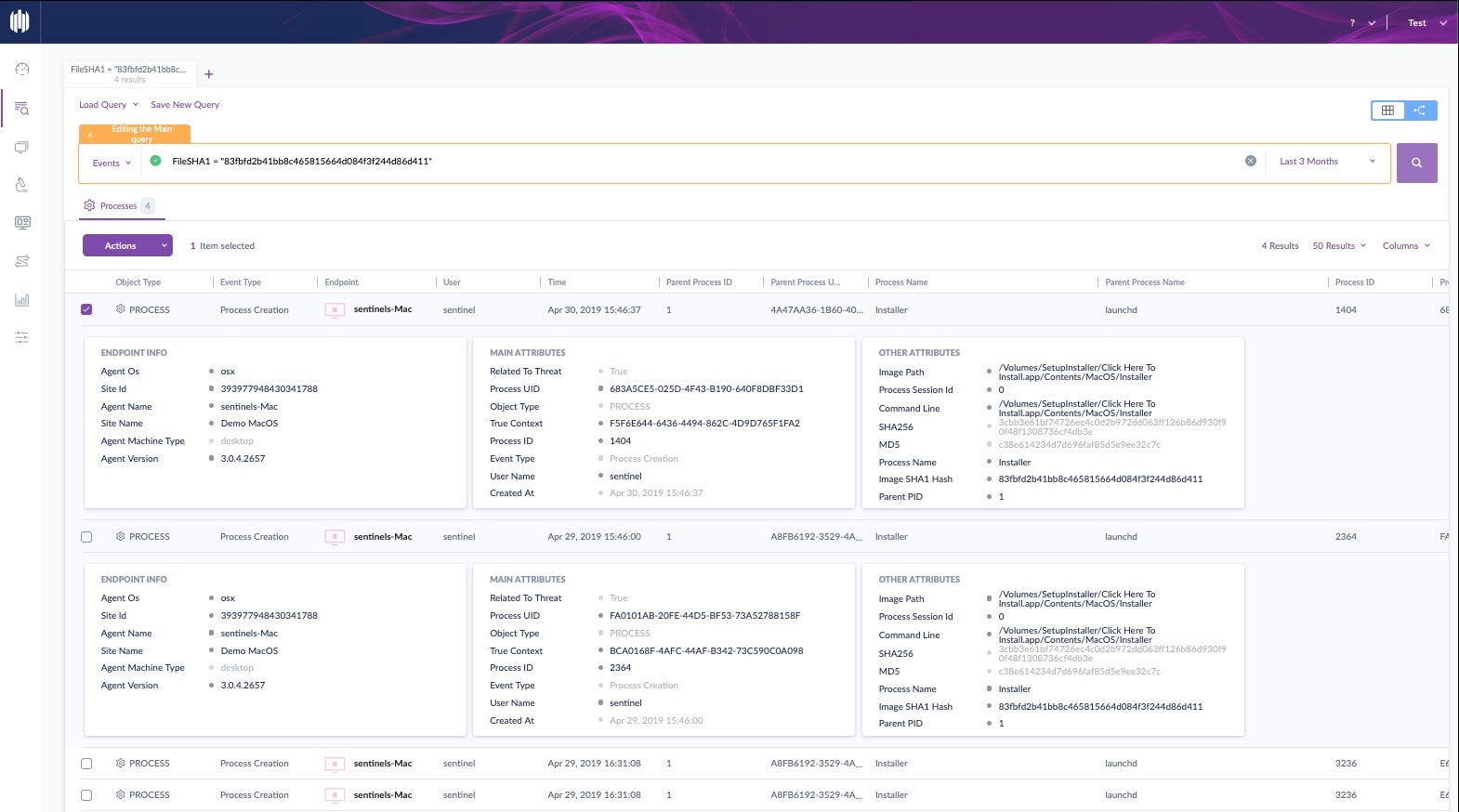
Great, we can see there’s been a few instances, but the magic doesn’t stop there. The hash search has led us to the TrueContext ID, which we can pivot off to really dive down the rabbit hole and see exactly what this file did: what processes it created, what files it modified, what URLs it contacted and so on. In short, we can build the entire attack storyline with just a few clicks from the file’s hash.
AI-Powered Cybersecurity
Elevate your security posture with real-time detection, machine-speed response, and total visibility of your entire digital environment.
Get a DemoConclusion
Hashes are a fundamental tool in computer security as they can reliably tell us when two files are identical, so long as we use secure hashing algorithms that avoid collisions. Even so, as we have seen above, two files can have the same behaviour and functionality without necessarily having the same hash, so relying on hash identity for AV detection is a flawed approach.
Despite that, hashes are still useful for security analysts for such things as sharing IOCs and threat-hunting, and you will undoubtedly encounter them on a daily basis if you work anywhere in the field of computer and network security.
Like this article? Follow us on LinkedIn, Twitter, YouTube or Facebook to see the content we post.
Read more about Cyber Security
- The Enemy Within – Top 7 Most Disturbing Data Breaches in 2018
- 5 Ways a CISO Can Tackle the CyberSecurity Skills Shortage Now
- How Malware Can Easily Defeat Apple’s macOS Security
- What Is Windows PowerShell (And Could It Be Malicious)?
Hashing FAQs
Hashing is a one-way encryption technique that converts data into a fixed-length string of characters. You can’t reverse this process to get the original data back. It works like a digital fingerprint – the same input always produces the same hash, but different inputs create completely different outputs. Hashing protects passwords, verifies file integrity, and ensures data hasn’t been tampered with. It’s essential for blockchain technology and digital signatures.
A common example is SHA-256 hashing the word “hello” to produce “2cf24dba4f21d4288094c30e2ede82c380cac19544bb5c4ab02f5b2db38500d3”. If you change just one character to “Hello”, you get a completely different hash. Password systems use hashing – when you create a password, it gets hashed and stored. When you log in, your entered password gets hashed and compared to the stored hash. File integrity checking also uses hashing to detect changes.
Hashing ensures data integrity by detecting any unauthorized changes. It protects passwords by making them unreadable even if databases get breached. You can verify file downloads haven’t been corrupted or infected with malware. Hashing enables digital signatures and secure communication protocols. It’s fundamental to blockchain technology and cryptocurrency security. Without hashing, you couldn’t trust that data remains unchanged during transmission or storage.
The main hashing families are MD (Message Digest), SHA (Secure Hash Algorithm), and RIPEMD. MD5 produces 128-bit hashes but is now considered insecure. SHA-256 is currently the most widely used, producing 256-bit hashes. SHA-3 is the newest standard, designed to replace older algorithms. Each type varies in security strength, hash length, and computational requirements. Modern systems prefer SHA-256 or SHA-3 for security-critical applications.
Hashing is one-way and irreversible, while encryption is two-way and reversible. Hashing always produces fixed-length output regardless of input size. Encryption output length varies based on the input data. Hashing verifies data integrity, while encryption protects data confidentiality. You can decrypt encrypted data with the right key, but you can’t unhash data. Both serve different security purposes and often work together.
Hashing keeps data secure by making it impossible to reverse-engineer the original information. Even if attackers steal hashed passwords, they can’t easily determine the actual passwords. Any change to the original data produces a completely different hash, making tampering detectable. Hashing doesn’t require encryption keys, so there’s no key to compromise. It provides data integrity verification without exposing the actual content. This makes it ideal for password storage and file verification.
Hashing provides fast data retrieval and verification. It ensures data integrity without exposing the original content. Password security improves significantly when using proper hashing techniques. File integrity checking becomes simple and reliable. Hashing enables blockchain technology and secure transactions. It’s computationally efficient and doesn’t require key management. Digital signatures and authentication systems depend on hashing for security. Data deduplication and efficient storage management also benefit from hashing.
